
What is a Knowledge Graph? A Complete Overview
Betsy leads the customer success and implementation teams at Bloomfire and is a Certified Knowledge Manager (CKM) from KM Institute. Passionate about the people side of knowledge engagement and knowledge sharing, she brings real-world experience in tackling the challenges companies face with knowledge management.

A knowledge graph is one of the most transformative data architectures in modern AI and enterprise technology: a structured, interconnected network that doesn’t just store data, but represents meaning. Unlike traditional databases that organize information in flat rows and columns, knowledge graphs capture the rich web of relationships between real-world entities, enabling machines to reason, infer, and answer complex questions the way humans do.
From powering Google Search to driving fraud detection in banking, knowledge graphs have become foundational infrastructure for the intelligent enterprise. Below, we’ll explore how they’re defined, how they work, and why they’re becoming essential for organizations that want to make their knowledge AI‑ready.
What is a Knowledge Graph?
A knowledge graph is a knowledge base that uses a graph-structured data model to represent and operate on data. More specifically, it is a network of real-world entities such as objects, people, events, situations, or concepts, and the relationships that connect them. These relationships are stored, visualized, and reasoned over as a graph structure, which is where the term knowledge graph originates.
Core Building Blocks of a Knowledge Graph
A knowledge graph is built from three fundamental building blocks that work together to turn raw data into connected knowledge. Standardizing information into these shared components gives organizations a consistent way to model and reason about everything from people and processes to content and systems.

Nodes (Entities) represent the real-world “things” your organization cares about: customers, employees, products, locations, accounts, contracts, or even abstract concepts like satisfaction or churn. Each node represents a single, identifiable entity, so that every reference to that person, object, or idea can be anchored to the same place in the graph. This makes it possible to see everything related to that entity, like documents, transactions, or interactions, in a single, connected view.
Edges (Relationships) are the lines that connect those nodes and explain how they relate, using verbs like “founded,” “works for,” “owns,” “reported in,” or “located in.” Unlike a typical database join, these relationships are first-class citizens in the model, meaning they’re explicitly stored, typed, and searchable. That lets you ask multi-step questions like “which customers are tied to a specific product line through a particular partner” without stitching together multiple reports.
Labels and Properties add detail and context to both nodes and edges so the graph can support rich analysis instead of just basic linking. A person node might have properties like name, role, region, and hire date, while an “owns” relationship might include percentage ownership, effective date, or source system. These attributes give AI and humans enough context to filter, rank, and reason over the graph instead of treating every connection as equal.
Together, these elements turn loose facts into a structured representation of how things and people relate to one another. That structure enables both humans and AI systems to explore connections, spot patterns, and answer complex questions far more efficiently than with traditional table-based data alone.
Ontologies: How They Relate
Ontologies are machine-readable frameworks designed to provide a formal representation of a knowledge graph. An ontology defines the rules and structure of a knowledge graph, which entity types exist (e.g., Employee, Product, Customer), and how they can relate. Think of it as the blueprint that enforces consistency, enables logical inference, and ensures all data is interpreted uniformly across systems.
Example of a Knowledge Graph
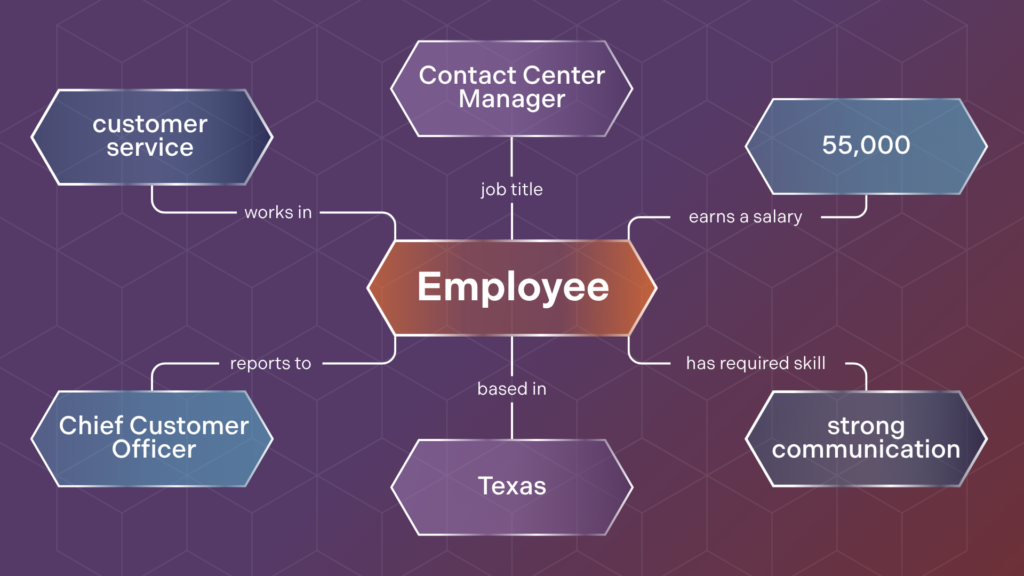
This knowledge graph illustrates how employee data can be organized as connected entities rather than isolated fields. The employee is the central node, and each surrounding node describes an important attribute or related entity, such as department, role, skill, location, compensation, and manager.
Each edge gives the connection meaning. Rather than storing “Customer Service,” “Texas,” or “$55,000” as disconnected text values, the graph labels those links with relationships like works in, based in, and earns, making the data easier to search, analyze, and reuse.
This structure shows why knowledge graphs are useful in company-wide knowledge management. Once relationships are explicit, teams can ask richer questions such as which employees work in Customer Service, who reports to the Chief Customer Officer, or which managers in Texas require strong communication skills.
How do Knowledge Graphs Work?
Knowledge graphs work by turning fragmented information from many systems into a connected, queryable map of entities and relationships. Instead of treating each record as an isolated row, they continuously integrate data, reconcile duplicates, and attach semantic meaning so everything can be explored as one cohesive graph. At a high level, that process typically looks like this:
- Ingest data from multiple sources. Data flows in from tools like CRMs, HR platforms, ticketing systems, data warehouses, and document repositories. Each source can contribute different perspectives on the same people, accounts, products, and processes, which the graph will later consolidate.
- Extract entities and relationships. Natural language processing and pattern-matching scan records and documents to identify key entities (such as people, companies, locations, and topics) and how they relate to each other. This step surfaces signals like who reports to whom, which customer owns which account, or which policy a given document supports.
- Resolve duplicates into a single node. The system then performs entity resolution so that variants like “J. Smith,” “Jordan Smith,” and an internal employee ID all map to the same underlying person. This consolidation prevents fragmentation and ensures that every interaction, document, and transaction tied to that individual rolls up to a single, authoritative node.
- Attach properties and classifications. Once entities and relationships are established, the graph enriches them with properties such as timestamps, values, tags, and confidence scores. These attributes allow users and AI agents to filter, rank, and analyze the graph based on recency, source, data type, or business importance.
- Store and query in a graph-optimized backend. The resulting structure lives in a backend designed for graph operations, making it fast to traverse multi-step paths like “employees in Texas who support strategic accounts in retail.” When users or AI agents run a query, graph query languages and reasoning engines follow the connections, infer missing links, and return answers that reflect the full context of the organization’s knowledge rather than a single isolated record.
Together, these activities reshape raw inputs into a navigable network of entities and relationships instead of a pile of disconnected records. That network becomes the backbone for smarter search, analytics, and AI experiences that can draw on the full context of your organization’s knowledge.
Why Are Knowledge Graphs Important?

Knowledge graphs transform scattered information into a connected fabric of entities and relationships that machines and people can both understand. Instead of forcing teams to jump between systems and reports, they provide a shared, always-current view of customers, employees, products, and processes. This makes it easier to answer complex questions, automate decisions, and plug AI into the business with confidence. Below are four of the key ways knowledge graphs deliver that impact.
1. Connecting Siloed Data
Most organizations store critical information across dozens of tools and formats, from CRMs and HR systems to shared drives and chat threads. A knowledge graph brings those silos together by linking records that refer to the same people, accounts, topics, and events into a single, coherent network. As a result, teams can see the full story around a customer, issue, or initiative in one place instead of manually stitching it together every time.
2. Providing Context and Meaning
Raw data is meaningless without context. A knowledge graph doesn’t just store that a transaction occurred for $10,000; it stores who made it, to whom, at what time, under what conditions, and how that relates to other transactions and entities. This contextual richness is what turns data into actionable intelligence.
3. Enabling Explainable AI
One of the most critical challenges in modern AI is explainability: why did the model make that decision? AI knowledge graphs provide an audit trail for conclusions. Unlike black-box neural networks, where the decision-making process is completely hidden from humans, knowledge graph-powered AI shows exactly which relationships and data points contributed to each answer, making AI systems trustworthy and auditable.
4. Preserving Institutional Knowledge
Critical institutional knowledge often lives in the minds of experienced employees or is buried in disconnected documents. Knowledge graphs capture and codify this institutional memory, making it accessible and reusable across the organization, even after personnel changes. Recent knowledge management research notes that knowledge graphs are becoming a core pattern for integrating personal and organizational knowledge, helping organizations retain expertise, support onboarding, and enable more effective knowledge reuse at scale.
Turn Knowledge Into an Advantage
Bloomfire centralizes tribal knowledge for AI-ready context in a knowledge base.
Learn More
Knowledge Graph Use Cases
Knowledge graphs are already at work behind the scenes in the tools people use every day, from search engines to recommendation systems. In the enterprise, they shine wherever you need to connect many moving parts and ask complex questions across them. Below are some of the most impactful use cases that show how this plays out in practice.
Search and Information Retrieval
This is the most ubiquitous application. Search engines like Google use knowledge graphs to understand queries semantically and return direct answers, not just links. Knowledge graphs enable a search engine to understand that “mayor of New York” refers to a person, not a keyword. This directly powers rich Knowledge Panels, featured snippets, and answer boxes.
Healthcare and Biomedical Research
Healthcare knowledge graphs integrate patient data (genetic profiles, clinical histories, lab results) with medical literature and clinical guidelines to power personalized treatment plans. Researchers use them to discover new applications for existing drugs, map drug interactions, and accelerate clinical trial matching. A 2023 review of healthcare knowledge graphs concludes that they have “emerged as a powerful tool” for structuring medical knowledge and supporting biomedical research, clinical decision-making, and precision medicine by linking genes, diseases, drugs, and patient characteristics in a single, searchable graph.
Recommendation Systems
In e-commerce, knowledge graphs connect products with user preferences, purchase history, browsing behavior, and other customers’ actions to generate highly personalized recommendations. Amazon’s product graph is a prominent example, enabling suggestions like “customers who bought X also bought Y” based on deep relationship modeling rather than simple co-occurrence statistics.
Financial Fraud Detection and Risk Management
Banks and financial institutions use knowledge graphs to model complex networks of accounts, transactions, ownership structures, and behavioral patterns. By analyzing these relationships in real time, Graph Neural Networks can identify fraud rings and anomalous patterns that traditional rule-based systems miss entirely. Knowledge graphs are also used for Know Your Customer (KYC) checks, credit risk assessment, and regulatory compliance.
Cybersecurity and IT Operations
Knowledge graphs map IT infrastructure like devices, networks, users, permissions, and vulnerabilities into a unified semantic model. This allows security teams to perform multi-hop threat reasoning: if a device is compromised, the graph can instantly surface every user, system, and data asset that device has access to, enabling rapid impact assessment.
Company-wide Knowledge Management
Companies use internal knowledge graphs to connect employees, projects, documents, skills, and processes. This powers intelligent search, expert discovery, and onboarding acceleration, enabling new employees to navigate institutional context in days rather than months. As these internal graphs mature, they increasingly serve as the semantic backbone for enterprise AI, feeding more relevant context into retrieval-augmented generation, recommendation engines, and decision-support tools.
The Connection Between AI and Knowledge Graphs
Knowledge graphs increasingly serve as the “grounding layer” for AI and large language models (LLMs), providing a structured, contextual source of truth rather than relying solely on statistical patterns in text. In a 2024 survey on Graph Retrieval‑Augmented Generation (RAG), researchers found that using knowledge graphs in the retrieval layer improves factual accuracy and reduces hallucinations on knowledge‑intensive tasks compared to standard text‑only RAG. In practice, the knowledge graph acts as an external memory: the LLM retrieves entities and relationships from the graph before generating an answer, making responses more precise and easier to audit.
On the other hand, building a knowledge graph previously required significant manual effort from domain experts. Today, AI knowledge graphs reverse this relationship: machine learning models automatically extract entities and relationships from unstructured text at scale, dramatically accelerating graph construction and maintenance. NLP pipelines identify named entities, classify relationship types, and resolve ambiguous references, populating the graph continuously as new data arrives.
This creates a tight feedback loop: knowledge graphs give AI a reliable, structured foundation, and AI automates the hard work of building and updating those graphs at scale. Organizations that invest in both end up with AI that is smarter, more explainable, and more closely aligned with how their business actually works.
Why Knowledge Graphs Are Essential in AI-Powered KMS: From Bloomfire’s CTO
Bloomfire views a knowledge graph as the trusted orchestration layer for enterprise knowledge—a distributed system of truth that connects curated content, real-world usage, and outcomes across every system where knowledge lives. Rather than centralizing information, Bloomfire’s approach maps relationships among knowledge, people, and real business interactions—capturing not just what is known but what has been proven to work in real scenarios.
This enables AI to move beyond retrieval to agentic execution, where it can reason over trusted, governed knowledge, draw on context from past successful outcomes, and take action with confidence. With trust and governance at its core—ensuring every answer is verifiable, current, and permission-aware—the Bloomfire knowledge graph becomes the backbone for delivering reliable, context-aware intelligence that drives consistent decisions, powers high-stakes workflows, and continuously improves as the organization learns.
Utilizing Knowledge Graphs to Gain a Competitive Edge
AI Knowledge graphs give organizations a way to convert everyday operations into a continuously evolving map of how their business actually works. When that map is in place, leaders can see dependencies, risks, and opportunities faster than competitors who are still sifting through disconnected reports and systems.
Knowledge graphs also make it easier to plug AI into real work, because models can draw on a shared, well-structured representation of people, processes, and decisions. Organizations that invest in this foundation build a compounding advantage, as every new interaction enriches the graph, making future insights faster, sharper, and more defensible.
Make Your Knowledge Graph Real
Talk with Bloomfire about structuring your content as a knowledge graph.
Talk to an Expert!
These terms are often used interchangeably, but there is a distinction. A knowledge base is a general term for any structured repository of information. A knowledge graph is a specific type of knowledge base that uses a graph structure to represent relationships explicitly, and applies formal semantics to support reasoning and inference.
An ontology is the schema or blueprint of a knowledge graph. It defines what types of entities exist (Person, Organization, Product), what relationships are valid between them, and the rules governing those relationships. Without an ontology, a knowledge graph is just a collection of disconnected facts. The ontology gives it structure, consistency, and the ability to infer new knowledge.
Yes, and this is one of their most powerful features. AI-powered extraction pipelines use NLP to process unstructured text (documents, emails, articles) and automatically identify entities and relationships, which are then added to the graph. This means organizations can integrate their vast repositories of unstructured content alongside structured databases.
While knowledge graphs benefit virtually any data-intensive organization, the industries with the highest adoption and impact include healthcare and biomedical research (drug discovery, clinical decision support), financial services (fraud detection, risk management, compliance), technology (search engines, recommendation systems, AI assistants), and company knowledge management (expert discovery, onboarding, institutional memory).
Betsy leads the customer success and implementation teams at Bloomfire and is a Certified Knowledge Manager (CKM) from KM Institute. Passionate about the people side of knowledge engagement and knowledge sharing, she brings real-world experience in tackling the challenges companies face with knowledge management.

Why Your Software Company Needs a Knowledge Management Strategy

AI for Customer Service: A Practical Guide

What Your “Good Enough” Knowledge Management Software Is Actually Costing You

Estimate the Value of Your Knowledge Assets
Use this calculator to see how enterprise intelligence can impact your bottom line. Choose areas of focus, and see tailored calculations that will give you a tangible ROI.

Take a self guided Tour
See Bloomfire in action across several potential configurations. Imagine the potential of your team when they stop searching and start finding critical knowledge.